
Склады данных (DataWarehousing) и системы оперативной аналитической обработки данных
До сих пор мы рассматривали способы и возможные архитектуры информационных систем, предназначенных для оперативной обработки данных, т.е. для получения текущей информации, позволяющей решать повседневные проблемы корпорации. Однако у аналитических отделов корпорации и у высшего звена управляющего состава имеются и другие задачи: проанализировав поведение корпорации на рынке с учетом сопутствующих внешних факторов и спрогнозировав хотя бы ближайшее будущее, выработать тактику, а возможно, и стратегию корпорации. Понятно, что для решения таких задач требуются данные и прикладные программы, отличные от тех, которые используются в оперативных информационных системах. В последние несколько лет все более популярным становится подход, основанный на концепциях склада данных и системы оперативной аналитической обработки данных. Возможно, в российских условиях трудно производить долговременные прогнозы бизнес-деятельности (слишком изменчивы внешние факторы), но анализ прошлого и краткосрочные прогнозы будущего могут оказаться очень полезными.
Прежде чем перейти к обсуждению технических аспектов, коротко обсудим проблемы терминологии. Поскольку термины, связанные со складами данных не так давно появились и на английском языке, и смысл их постоянно уточняется, трудно найти правильные русскоязычные эквиваленты. На сегодняшний день "datawarehouse" разными авторами переводится на русский язык как "хранилище данных", "информационное хранилище", "склад данных". Поскольку термин "хранилище" явно перегружен (он соответствует и английским терминам "storage" и "repository"), в этом курсе мы будем использовать термин "склад данных". Еще хуже дела обстоят с термином "data mart". В четвертом номере журнала "СУБД" за 1996 г. в напечатанных подряд двух статьях авторы переводят этот термин как "витрина данных" и "секция данных" соответственно. Однако в Оксфордском толковом словаре единственным подходящем по смыслу толкованием смысла слова "mart" является "market place".
Чтобы не умножать число требуемых сущностей мы будем использовать термин "рынок данных" (обсуждение этого понятия отложим до пятой части курса). Конечно, постепенно терминология будет согласована, но это произойдет только тогда, когда склады данных будут активно использоваться в России.
В этом разделе мы не будем рассматривать возможные технологические приемы реализации складов данных, а обсудим соответствующие вопросы на концептуальном уровне. Начнем с того, что главным образом различает оперативные и аналитические информационные приложения с точки зрения обеспечения требуемых данных. Замечание: речь идет о так называемых OLAP-системах (от On-Line Analitical Processing), т.е. аналитических системах, помогающих принимать бизнес-решения за счет динамически производимых анализа, моделирования и/или прогнозирования данных.
- Основным источником информации, поступающей в оперативную базу данных является деятельность корпорации. Для проведения анализа данных требуется привлечение внешних источников информации (например, статистических отчетов). Тем самым, склад данных должен включать как внутренние корпоративные данные, так и внешние данные, характеризующие рынок в целом.
- Если для оперативной обработки, как правило, требуются свежие данные (обычно в оперативных базах данных информация сохраняется не более нескольких месяцев), то в складе данных нужно поддерживать хранение информации о деятельности корпорации и состоянии рынка на протяжении нескольких лет (для проведения достоверных анализа и прогнозирования). Как следствие, аналитические базы данных имеют объем как минимум на порядок больший, чем оперативные.
- Во многих достаточно крупных корпорациях одновременно существуют несколько оперативных информационных систем с собственными базами данных (как мы уже отмечали в этом курсе, это не очень хорошо, но часто неизбежно по историческим причинам). Оперативные базы данных могут содержать семантически эквивалентную информацию, представленную в разных форматах, с разным указанием времени ее поступления, иногда даже противоречивую (например, из-за ошибок ввода данных).
Склад данных корпорации должен содержать единообразно представленные данные из всех оперативных баз данных. Эта информация должна максимально полно соответствовать текущему содержанию оперативных баз данных и быть согласованной. Отсюда следует необходимость наличия компонента склада данных, извлекающего информацию из оперативных баз данных и "очищающего" эту информацию. - Оперативные информационные системы проектируются и разрабатываются в расчете на решение конкретных задач. Обычно набор запросов к оперативной базе данных становится известным уже на этапе проектирования системы. Информация из базы данных выбирается часто и небольшими порциями. Поэтому при проектировании оперативной базы данных можно и нужно учитывать этот заранее известный набор запросов (с известными оговорками в связи с возможными переделками информационной системы). Набор запросов к аналитической базе данных предсказать невозможно. Склады данных для того и существуют, чтобы отвечать на неожиданные (ad hoc) запросы аналитиков. Можно рассчитывать только на то, что запросы будут поступать не слишком часто и затрагивать большие объемы информации. Размеры аналитической базы данных стимулируют использование запросов с агрегатами (сумма, минимальное, максимальное, среднее значение и т.д.).
- Оперативные базы данных по своей природе являются сильно изменчивыми. Это учитывается в используемых СУБД. В частности, распространенным механизмом индексации являются B-деревья, модификация которых выполняется достаточно быстро, а строки в таблицах хранятся неупорядоченно. Аналитические базы данных меняются только тогда, когда в них загружается оперативная или внешняя информация. В результате оказывается разумным использовать другие, более быстрые при выполнении операций массовой выборки методы индексации, поддерживать упорядоченность информационных массивов, сохранять заранее вычисленные значения агрегатных функций и т.д.
- Если для оперативных информационных систем обычно хватает защиты информации на уровне таблиц (по правилам SQL-ориентированных баз данных), то информация аналитических баз данных настолько критична для корпорации, что для ее защиты требуются более тонкие приемы (например, при использовании реляционных баз данных установка индивидуальных привилегий доступа для индивидуальных строк и/или столбцов таблицы).
С учетом приведенных замечаний общая архитектура склада данных и системы аналитической обработки данных может выглядеть так, как показано на рисунке 2.10.
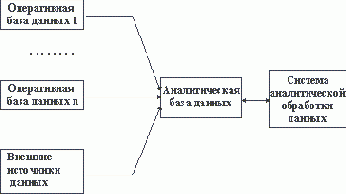
Рис. 2.10. Схематическое представление архитектуры аналитической информационной системы
В 1993 г. основоположник реляционного подхода к организации баз данных Эдвар Кодд, исходя из потребностей систем динамической аналитической обработки данных, сформулировал 12 основных требований к системам, поддерживающим аналитические базы данных. Мы приведем изложение этих требований, чтобы представить точку зрения проектировщика и разработчика системы аналитической обработки данных.
- Многомерное концептуальное представление данных. Это требование возникает по той причине, что бизнес-пользователь естественно представляет историю и деятельность своей корпорации многомерными (например, одно измерение - время, другое - заказчики, третье - производимая продукция и т.д.). OLAP-модели должны поддерживать это представление и, естественно, оно должно хотя бы в какой-то мере опираться на возможности аналитической базы данных.
- Прозрачность. Для бизнес-пользователя не должно быть существенно, где конкретно расположены средства динамического анализа данных. При разработке OLAP-систем следует придерживаться подхода открытых систем, что позволит размещать средства анализа в любом узле корпоративной сети.
- Доступность. Логическая схема, с которой работает OLAP-система, должна отображаться в схемы разнородных физических хранилищ данных. При доступе к данным должно поддерживаться их единое и согласованное представление.
- Согласованная эффективность производства отчетов. Эта эффективность не должна деградировать при увеличении числа измерений.
- Архитектура "клиент-сервер". Серверный компонент OLAP-системы должен быть достаточно развитым, чтобы разнообразные клиенты могли подключаться к нему с минимальными усилиями и затратами на дополнительное "интегрирующее" программирование.
- Родовая многомерность. Структурные и операционные возможности работы с каждым измерением данных должны быть эквивалентны.
Для всех измерений должна существовать только одна логическая структура. Любая функция, применимая к одному измерению, должна быть применима к любому другому измерению. - Управление динамическими разреженными матрицами. Сервер OLAP-системы должен уметь эффективно хранить и обрабатывать разреженные матрицы. Физические методы доступа должны быть разнообразны, включая прямое вычисление, B-деревья, хэширование или комбинации этих методов.
- Поддержка многопользовательского режима. OLAP-система должна поддерживать многопользовательский доступ к данным (по выборке и изменению), обеспечивая целостность и безопасность данных.
- Неограниченные операции между измерениями. При выполнении многомерного анализа данных все измерения создаются и обрабатываются единообразно. OLAP-система должна быть в состоянии выполнять соответствующие вычисления между измерениями.
- Интуитивное манипулирование данными. Манипуляции, подобные смене пути анализа или уровня детализации, должны выполняться с помощью прямого воздействия на элементы OLAP-модели без потребности использовать меню или другие вспомогательные средства.
- Гибкая система отчетов. Бизнес-пользователь должен иметь возможность манипулировать данными, анализировать и/или синтезировать, а также просматривать их таким образом, как ему захочется.
- Неограниченное число измерений и уровней агрегации. OLAP-сервер должен поддерживать не менее 15 измерений для каждой аналитической модели. Для каждого измерения должно допускаться неограниченное число определяемых пользователями агрегатов.
Основным выводом из материала этого раздела является то, что подход складов данных еще слишком молод, чтобы вокруг него сложился круг общепринятых понятий, терминов, технологических приемов. Тем не менее, он кажется настолько важным и перспективным, что многие компании (в том числе и ведущие производители СУБД) ведут активную работу, чтобы быть в авангарде этого направления. Существующие идеи и реализации мы рассмотрим в пятой части курса.